1. 스택의 이해와 ADT 정의
∙ 스택은 ‘먼저 들어간 것이 나중에 나오는 자료구조’ 로서 초코볼이 담겨있는 통에 비유할 수 있다.
∙ 스택은 ‘LIFO(Last-in, First-out) 구조’의 자료구조이다.
▣ 스택의 기본 연산
∙ 통에 초코볼을 넣는다. push
∙ 통에서 초코볼을 꺼낸다. pop
∙ 이번에 꺼낼 초코볼의 색이 무엇인지 통 안을 들여다 본다. peek
※ 일반적인 자료구조의 학습에서 스택의 이해와 구현은 어렵지 않다. 오히려 활용의 측면에 서 생각할 것들이 많다!

※ ADT를 대상으로 배열 기반의 스택 또는 연결 리스트 기반의 스택을 구현할 수 있다
2. 스택의 배열 기반 구현

∙ 인덱스 0의 배열 요소가 '스택의 바닥(초코볼 통의 바닥)'으로 정의되었다.
∙ 마지막에 저장된 데이터의 위치를 기억해야 한다.
∙ push : Top을 위로 한 칸 올리고, Top이 가리키는 위치에 데이터 저장
∙ pop : Top이 가리키는 데이터를 반환하고, Top을 아래로 한 칸 내림
void Stackinit(Stack* pstack)
{
pstack->topIndex = -1; // 비어있음
}
int IsEmpty(Stack* pstack)
{
if (pstack->topIndex == -1)return true;
else
return false;
}
void SPush(Stack* pstack, Data data)
{
pstack->topIndex += 1;
pstack->stackArr[pstack->topIndex] = data;
}
//빼는게 아니라, topIndex를 줄여가면서 -1이 될떄까지 읽는다
Data SPop(Stack* pstack)
{
int rIdx;
if (IsEmpty(pstack))
{
cout << "Stack NULL " << endl;
}
rIdx = pstack->topIndex;
pstack->topIndex -= 1;
return pstack->stackArr[rIdx]; //
}
Data SPeek(Stack* pstack)
{
if (IsEmpty(pstack))
{
cout << "Stack NULL " << endl;
}
return pstack->stackArr[pstack->topIndex];
}
int main()
{
Stack stack;
Stackinit(&stack);
SPush(&stack,1);
SPush(&stack, 2);
SPush(&stack, 3);
SPush(&stack, 4);
SPush(&stack, 5);
while (!IsEmpty(&stack))
cout << SPop(&stack) << endl;
return 0;
}
3. 스택의 연결 리스트 기반 구현

저장된 순서의 역순으로 데이터(노드)를 참조(삭제) 하는 연결 리스트가 바로 연결 기반의 스택이다
typedef struct _node
{
Data data;
struct _node* next;
}Node;
typedef struct _listStack
{
Node* head;
}ListStack;
typedef ListStack Stack;
void Stackinit(Stack* pstack)
{
pstack->head = NULL; // 비어있음
}
int IsEmpty(Stack* pstack)
{
if (pstack->head == NULL)return true;
else
return false;
}
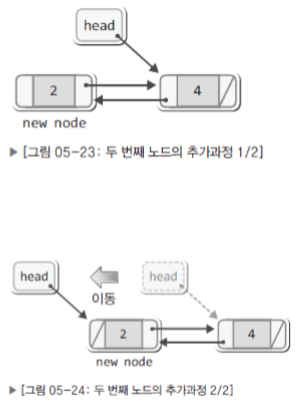
void SPush(Stack* pstack, Data data)
{
Node* newNode = new Node();
newNode->data = data;
newNode->next = pstack->head;
pstack->head = newNode;
}
Data SPop(Stack* pstack)
{
Data rdata;
Node* rnode;
if (IsEmpty(pstack))
{
cout << NULL << endl;
}
rdata = pstack->head->data;
rnode = pstack->head;
pstack->head = pstack->head->next;
delete rnode;
}
Data SPeek(Stack* pstack)
{
if (IsEmpty(pstack))
{
cout << "Stack NULL " << endl;
}
return pstack->head->data;
}
int main()
{
Stack stack;
Stackinit(&stack);
SPush(&stack,1);
SPush(&stack, 2);
SPush(&stack, 3);
SPush(&stack, 4);
SPush(&stack, 5);
while (!IsEmpty(&stack))
cout << SPop(&stack) << endl;
return 0;
}'프로그래밍 > 자료구조' 카테고리의 다른 글
| 8. 트리(Tree) (0) | 2019.06.11 |
|---|---|
| 7. 큐 (Queue) (0) | 2019.06.10 |
| 5. 원형 연결 리스트 3 (원형 + 양방향) (0) | 2019.06.06 |
| 4. 연결 리스트 2 (연결리스트 + 더미노드 + 정렬삽입) (0) | 2019.06.05 |
| 3. 연결리스트 1 (ADT + 배열기반 연결리스트) (0) | 2019.06.05 |