1. 연결 리스트의 개념적인 이해


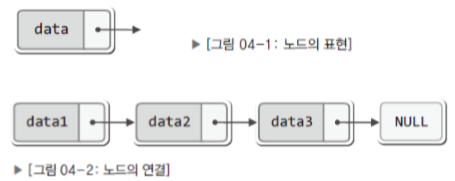
//노드
typedef struct _node
{
int data; //현재 데이터
struct _node * next; //다음 노드를 가르킬 포인터
} Node;
▶ 데이터 초기화
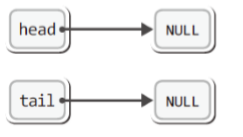
▶ 데이터 삽입

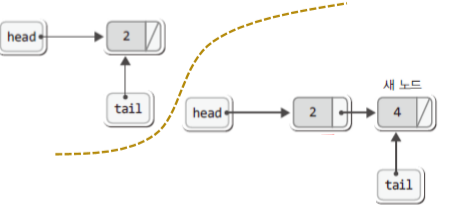

▶ 데이터 조회
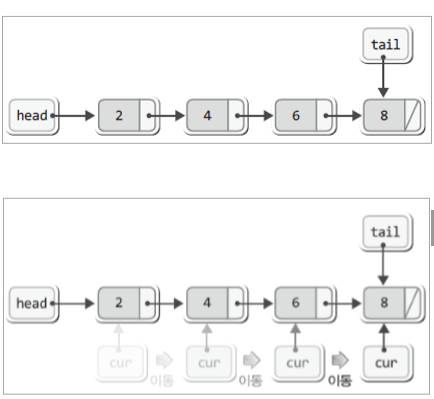
※ 머리부터 꼬리까지 순회하면서 조회해야 한다.
※ 중간에 있는 것을 조회 할라면 역시나 순회 비용이 든다
▶ 데이터 삭제

※ 삭제를 하고 나서 머리 및 꼬리는 다음 노드와 연결을 해주어야 한다.
※ 전체 삭제의 경우에는 무관함
2.



void SetSortRule(List * plist, int (*comp)(LData d1, LData d2))
{
plist->comp = comp;
}
//2개 인자로 전달이 가능한 함수의 예
int WhoIsPrecede(LData d1, LData d2) // typedef int LData;
{
if(d1 < d2)
return 0; // d1이 정렬 순서상 앞선다.
else
return 1; // d2가 정렬 순서상 앞서거나 같다.
}
//등록예시
SetSortRule(&myList , WhoIsPrecede); //리스트와 2인자가 같은 함수
※ 이렇듯 결정된 약속을 근거로 함수가 정의되어야 하며, 연결 리스트 또한 이 를 근거로 구현되어야 한다.
int cr = WhoIsPrecede(D1, D2)Cr에 저장된 값이 0이라면 , head . . . D1 . . D2 . . . tail
D1이 head에 더 가깝다.
Cr에 저장된 값이 1이라면, head . . . D2 . . D1 . . . tail
D2가 head에 더 가깝다



▶ 더미 노드 연결 리스트 구현: 초기화
void ListInit(List* pList)
{
pList->head = new Node();
pList->head->next = NULL;
pList->comp = NULL; //정렬기준
pList->numOfData = 0;
}

▶ 더미 노드 연결 리스트 구현: 삽입
void FInsert(List* pList, LData data)
{
Node* newNode = new Node();
newNode->data = data;
newNode->next = pList->head->next;
pList->head->next = newNode;
(pList->numOfData)++;
}
void SInsert(List* pList, LData data)
{
}
void ListInsert(List* pList, LData data)
{
if (pList->comp == NULL) //정렬기준
FInsert(pList, data);
else
SInsert(pList, data);
}
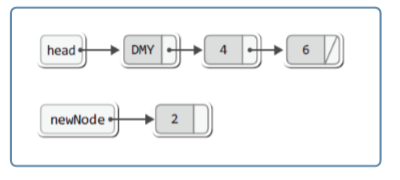
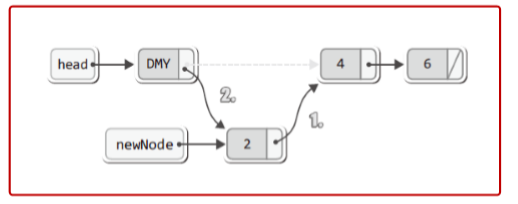
※ 모든 경우에 있어서 동일한 삽입과정을 거친다는 것이 더미 노드 기반 연결 리스트의 장점
▶ 더미 노드 연결 리스트 구현: 참조
int LFirst(List* pList, LData* pdata)
{
if (pList->head->next == NULL) //더미노드가 널이라면 반환할 데이터가 없다
return false;
pList->before = pList->head; //before는 더미 노드를 가리킥함
pList->cur = pList->head->next; //cur은 첫 번쨰 노드를 가리키게 함
*pdata = pList->cur->data;
return true;
}
int LNext(List* pList, LData* pdata)
{
if (pList->head->next == NULL) //더미노드가 널이라면 반환할 데이터가 없다
return false;
pList->before = pList->cur; //cur이 가리키던 것을 befor가 가리킴
pList->cur = pList->cur->next; //cur은 그 다음 노드를 가리킴
*pdata = pList->cur->data;
return true;
}

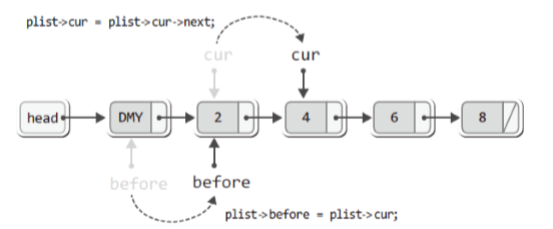
▶ 더미 노드 연결 리스트 구현: 삭제
LData LRemove(List* pList)
{
Node* rpos = pList->cur;
LData rdata = rpos->data;
pList->before->next = pList->cur->next;
pList->cur = pList->before;
delete rpos;
(pList->numOfData)--;
return rdata;
}

※ cur은 삭제 후 제조정의 과정을 거쳐야 하지만,
before는 LFirst or LNext 호출 시 재설 정되므로 재조정의 과정이 불필요하다

3. 연결 리스트의 정렬 삽입의 구현
▶ 단순 연결 리스트의 정렬 관련 요소 세 가지
∙ 정렬기준이 되는 함수를 등록하는 SetSortRule 함수
∙ SetSortRule 함수 통해 전달된 함수정보 저장을 위한 LinkedList의 멤버 comp
∙ comp에 등록된 정렬기준을 근거로 데이터를 저장하는 SInsert 함수
※“SetSortRule 함수가 호출되면서 정렬의 기준이 리스트의 멤버 comp에 등록되면,
SInsert 함수 내에서는 comp에 등록된 정렬의 기준을 근거로 데이터를 정렬하여 저장한다.”
1. SetSortRule 함수의 호출을 통해서 .
2. 멤버 comp가 초기화되면.
3. 정렬 관련 SInsert 함수가 호출된다
void SetSortRule(List * plist, int(*comp)(LData d1, LData d2))
{
plist->comp = comp;
}typedef struct _linkedList
{
Node * head;
Node * cur;
Node * before;
int numOfData;
int (*comp)(LData d1, LData d2);
} LinkedList;void ListInsert(List* pList, LData data)
{
if (pList->comp == NULL) //정렬기준
FInsert(pList, data);
else
SInsert(pList, data);
}
void SInsert(List* pList, LData data)
{
Node* newNode = new Node();
Node* pred = pList->head;
newNode->data = data;
// 새 노드가 들어갈 위치를 찾기 위한 반복문
while (pred->next != NULL &&
pList->comp(data, pred->next->data) != 0) // 새 노드의 값(data)과 더미 노드 다 음 데이터(pred->next->data)를 비교해서 data가 더 크다
{
//comp 반환이 1이라면
pred = pred->next; // 다음 노드로 이동, (뒤 노드로 이동)
}
newNode->next = pred->next;
pred->next = newNode;
(pList->numOfData)++;
}


while(pred->next != NULL && plist->comp(data, pred->next->data) != 0)
{
pred = pred->next; // 다음 노드로 이동
}
▶ comp의 반환 값과 그 의미
plist->comp(data, pred->next->data) != 0) 1. comp가 0을 반환
첫 번째 인자인 data가 정렬 순서상 앞서서 head에 더 가까워야 하는 경우
if(data < pred->next->data) return 0;
2. comp가 1을 반환
두 번째 인자인 pred->next->data가 정렬 순서상 앞서서 head에 더 가까워야 하는 경우
if(data >= pred->next->data) return 1;
▶ 정렬의 기준을 설정하기 위한 함수의 정의
∙ 두 개의 인자를 전달받도록 함수를 정의한다.
∙ 첫 번째 인자의 정렬 우선순위가 높으면 0을, 그렇지 않으면 1을 반환한다
//오름차순 정렬을 위한 함수의 정의
int WhoIsPrecede(int d1, int d2)
{
if(d1 < d2) return 0; // d1이 정렬 순서상 앞선다.
else return 1; // d2가 정렬 순서상 앞서거나 같다.
}
'프로그래밍 > 자료구조' 카테고리의 다른 글
| 6. 스택(Stack) (0) | 2019.06.07 |
|---|---|
| 5. 원형 연결 리스트 3 (원형 + 양방향) (0) | 2019.06.06 |
| 3. 연결리스트 1 (ADT + 배열기반 연결리스트) (0) | 2019.06.05 |
| 2. 재귀(Recursion) (0) | 2019.06.04 |
| 1. 자료구조와 알고리즘의 이해 (0) | 2019.06.04 |